
今回はアルゴリズムについてご紹介いたします!
みなさんはアルゴリズムについてどれくらいご存じでしょうか…普段よく聞くけど深く考えたことはないという方も多いのではないでしょうか?
アルゴリズムというのは、「ある問題を解決する際の手順」となります。アルゴリズムという言葉はIT業界においてかなり重要な単語なので必ず押さえておきましょう!
このアルゴリズムには色々種類があり、その表現方法も多種多様となっています。まずアルゴリズムの学習をするにあたり実際にどのような表現方法があるのか見ていきましょう!
(アルゴリズムそのものについては表現方法の説明の後に行います。)
アルゴリズムの表現方法
アルゴリズムは以下のようんな表現方法が存在します。
・文章
・フローチャート(流れ図)
・数式
・プログラム言語
今回は「数値を絶対値に変換するアルゴリズム」を上記の表現方法を用いて一つ一つ解説します!
文章
文章で「数値を絶対値に変換するアルゴリズム」を表現しようとすると以下のようになります。
(1)x<0ならば(2)、x≧0ならば(3)へ
(2)-x→x
(3)xを返す
文章の最大のメリットは数学記号と文字で構成されているのでそれさえ読むことができれば専門的な知識は一切不要でアルゴリズムが理解できる点です。
フローチャート
フローチャート(流れ図)というのは「アルゴリズムを図形などを用いて視覚的にわかりやすく表した図」です。「数値を絶対値に変換するアルゴリズム」をフローチャートで表現すると以下のようになります。
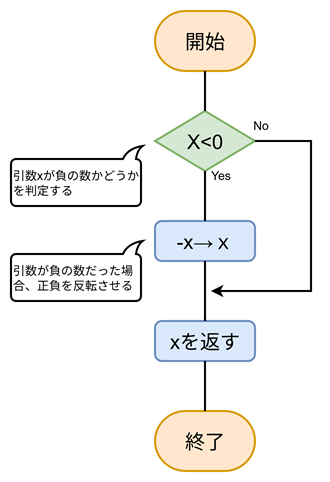
フローチャート(流れ図)で使用する記号についてはJIS(日本産業規格)によって規格化されており、基本情報技術者試験で頻出の5種類を以下の表に示します。名称は問われませんが、形と役割については覚える必要があります!
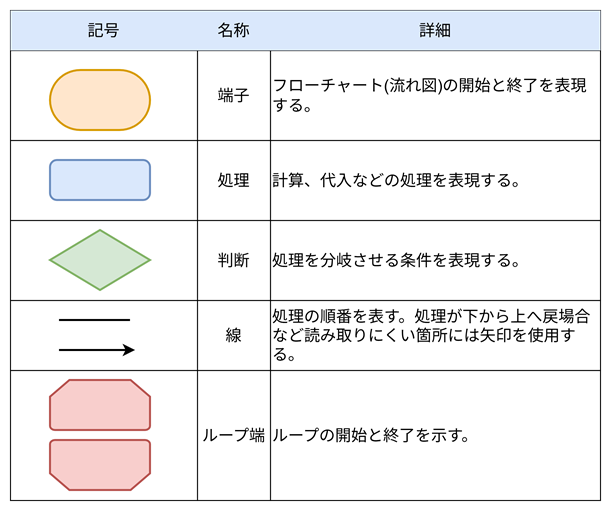
ただし、ループ端の記号に関して、記号の中に繰り返しの条件が記入されますが、条件の記入方法については必ず問題文中に中期されるので覚える必要はありません!
数式
「数値を絶対値に変換するアルゴリズム」を数式で表現すると以下の式になります。
ここでいう「」は関数を表す記号です。関数について説明します。
関数
関数というのは、複数の処理を一つにまとめたもののことをいいます。ある特定の処理、一連の処理を関数と定義しておくことで、その複数処理を何度でも関数名だけで再利用できるためプログラム内で同じ処理を複数回書かずに済みます。
関数を使う上で必ず覚えておかないといけないのが以下の2つです。
・引数:関数に渡す値
・戻り値(返り値):関数が返す値(結果)
プログラミング言語
「絶対値に変換するアルゴリズム」をプログラミング言語で表現すると以下のようになります。
(今回はC言語で書いていますが、言語によって記述方法が違うことには気を付けてください!
ただ、基本情報技術者試験ではプログラミング言語ごと特有の書式については一切問われないのでそこはご安心ください。)
f(x){
if(x < 0){
return -x;
}else{
return x;
}
}
(ここは言語の説明なので読み飛ばしても問題ありません!)
まず、「if(x < 0)」ですがこれはxが0より小さいときにそれに続く「{}」の中を実行するという条件分岐を表しています。そして「else」ですが、これはifと一緒に使うものでifが成り立たないとき、つまり今回でいうと「x≧0」の場合、その後ろに続く「{}」が実行されます。
基本情報技術者試験において押さえておいてほしい言葉は「if」「else」「then」「return」の4つです。
| 言葉 | 意味 |
|---|---|
| if | 「もし~なら」 ifの後ろに条件を記述する。 |
| else | 「もし~でないなら」 ifの条件に当てはまらないときの処理を後ろに記述する。 |
| then | ifの条件が成立する際の処理を記述する |
| return | 後ろに戻り値を記述する。 |
アルゴリズムの種類
冒頭ご説明しましたが、アルゴリズムというのは「ある問題を解決する際の手順」となります。
また「種類」といっているのは「コップ」「水筒」は「液体を入れる道具」や、「ボールペン」「鉛筆」は「書くための道具」といった具合に、アルゴリズムもある程度その「用途・目的」によって分類分けされているので「種類」といっています。
基本情報技術者試験においては以下3種類のアルゴリズムについて出題されます。
(1)整列アルゴリズム
(2)探索アルゴリズム
(3)再起的アルゴリズム
少し難しい部分もあるかもしれませんがかみ砕いて説明しますので、一緒に頑張っていきましょう
整列アルゴリズム
整列アルゴリズムというのは、データをある特定の順番に並べるアルゴリズムのことを指します。別名「ソートアルゴリズム」ともいいます。
主な整列アルゴリズムを以下の表に示します。
| アルゴリズム名 | 詳細 |
|---|---|
| バブルソート | 配列の先頭から順番に隣合うデータを比較し、順序が間違っていたら入れ替えることを繰り返すことで整列させるアルゴリズム |
| 選択ソート | 配列の先頭から順番にデータを比較し、最小のデータを見つけ、見つけた最小のデータを先頭のデータと入れ替えることを繰り返すことでっ整列させるアルゴリズム |
| 挿入ソート | 整列された要素を持つ配列に、未整列のデータを適切な場所に入れるアルゴリズム |
| クイックソート | 「基準値」よりも大きいグループと小さいグループに分け、それを分けたグループに対しても繰り返し行うことで整列させるアルゴリズム |
バブルソート
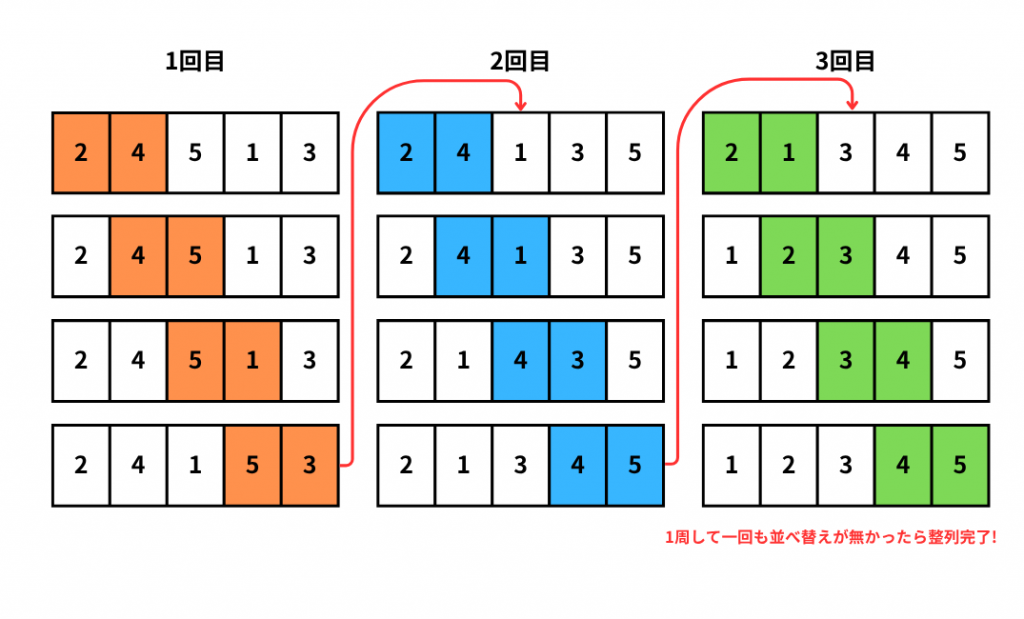
バブルソート(Bubble Sort)というのは「隣り合う要素の大小を比較し、順序が逆の場合入れ替える。」というのを繰り返し行う整列アルゴリズムです。
泡(Bubble)が液体中から浮かんでくる様子とデータが整列される様子が似ていることからこの名前が付けられました。計算量(計算量については後程ご紹介します!)が多くなるため大量データの処理には不向きとなります。
選択ソート
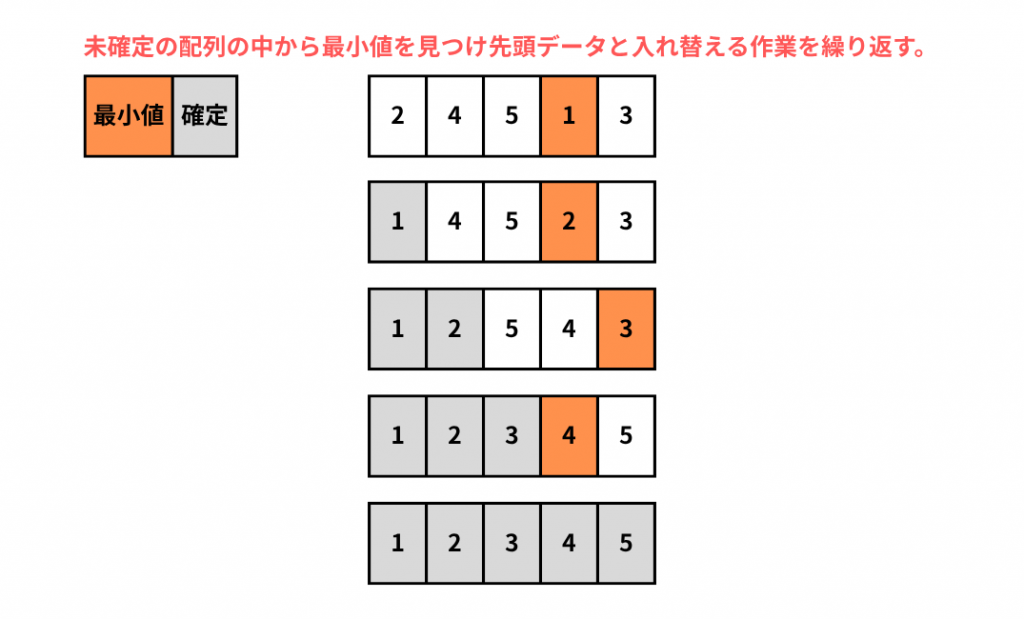
選択ソート(Selection Sort)というのは「配列の最小値(あるいは最大値)を持つ要素を探してそれを配列の先頭要素と交換する。」とうのを繰り返し行う整列アルゴリズムです。
配列の中から要素を選んでいるのでこの名前がついています。
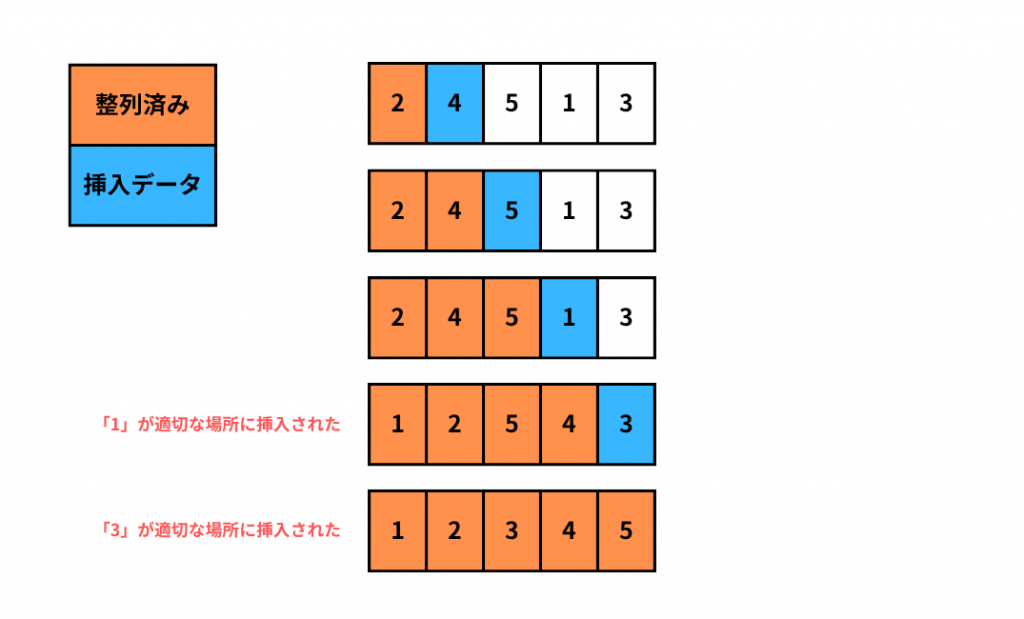
挿入ソート
挿入ソート(Insertion Sort)というのは、整列済みの配列の適切な位置に、未整列のデータを挿入する整列アルゴリズムです。
データがほとんど整列されている場合計算量が少なく高速に処理されます。
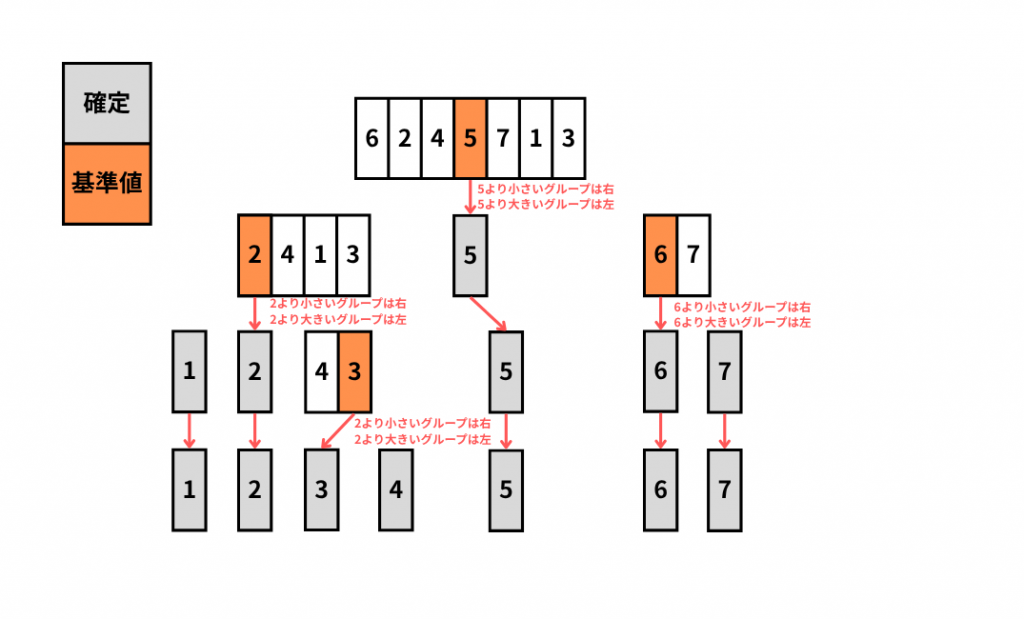
クイックソート
クイックソートというのはデータの全体を「基準値(ピポッド)より小さいグループ」「基準値より大きいグループ」に分けるという処理を繰り返すことでデータの並べ替えを行う整列アルゴリズムです。ちなみに今まで紹介してきたなかで最も高速(クイック)なアルゴリズムなので基本情報技術者の試験で最も問われやすくなっています。
探索アルゴリズム
探索アルゴリズムというのは、ある特定のデータを見つけ出すアルゴリズムのことを指します。
主な探索アルゴリズムを以下表に示します。
| アルゴリズム名 | 詳細 |
|---|---|
| 線形探索法 | 先頭のデータより順番に1つずつ照らし合わせることで目的のデータを見つける探索アルゴリズム。 |
| ハッシュ法 | ハッシュ表を使用し目的のデータを見つけ出す探索アルゴリズム。 |
| 2分探索法 | 調べる範囲を半分、また半分と切り分けていくことによって目的のデータを見つけ出す探索アルゴリズム。 |
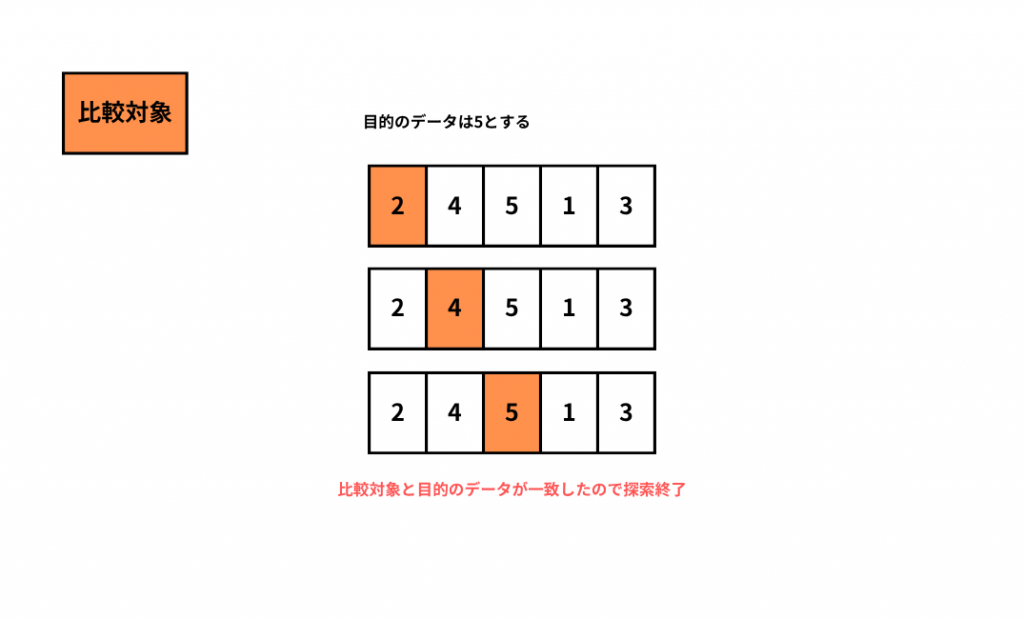
線形探索法
線形探索法というのは、データの先頭から順番に1つづ目的のデータと照合することによって探し出す探索アルゴリズムです。
ハッシュ法
ハッシュ法というのは、探索対象のデータをハッシュに変換し、このハッシュ値を使用し目的のデータを見つけ出す探索アルゴリズムです。ハッシュ法は別名ハッシュ表探索とも呼ばれています。
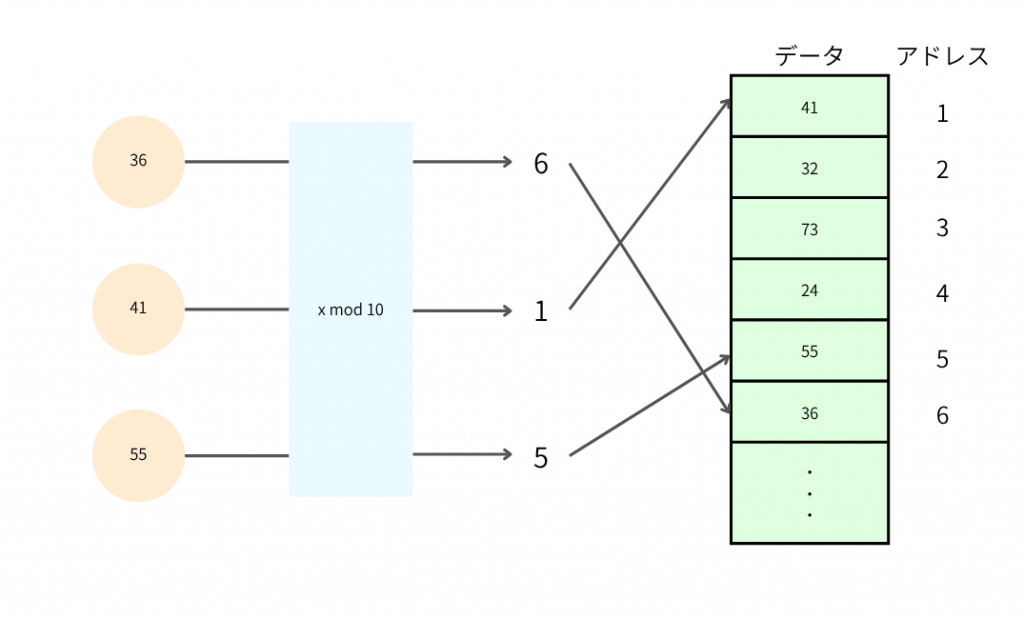
例として上の図で「55」をハッシュ法を持っちいることで探索してみましょう。
ハッシュ法ではハッシュ関数を用いて探索したいデータをハッシュ値に変換します。ハッシュ値というのはハッシュ関数の出力のことをいいます。
有名なハッシュ関数に「mod(剰余)」があります。modとは割り算の余りを指します。
例えば「52 mod 10」は「2」となります。
目的のデータはハッシュ値を要素番号として、配列の要素に格納されます。ハッシュ値を要素場sん号に持つ配列のことを「ハッシュ表」といいます。ハッシュ表ではハッシュ値を指定することで目的のデータの格納場所に一回の探索でアクセスできます。
つまり上の図だと、要素番号「5」を見れば、探索対象の「55」が一回で見つけられます
ただ、ハッシュ法には弱点があります。それは「衝突」が起こる可能性があるということです。
衝突というのは入力値が違うものなのに同じハッシュ値になることをいいます。
「x mod 10」の場合、「25」と「55」はどちらも「5」となり、衝突が起きてしまします。
したがっ別の方法でこの衝突を回避する必要があり計算量が増えてしまうデメリットがあります。
基本情報技術者試験においてはその回避する方法自体は問われませんが、「ハッシュ法のデメリットは衝突が起こる可能性がある」ということを問われます。
2分探索法
2分探索法というのは、調べる範囲を半分に分割していくことで目的のデータを見つけ出す探索アルゴリズムです。
2文探索法には以下のような特徴があります。
・データを探索法を使用する前に整列させておかなければならない
・データを2つに分割しながら探索する
2文探索法は効率の良い探索アルゴリズムですがデータをあらかじめ昇順もしくは降順でデータをソートしておく必要があるデメリットがあります。
では以下の図で「1~11」のデータが昇順で並んでいる配列の中から「7」という数字を2文探索法によって取り出す方法を説明します。
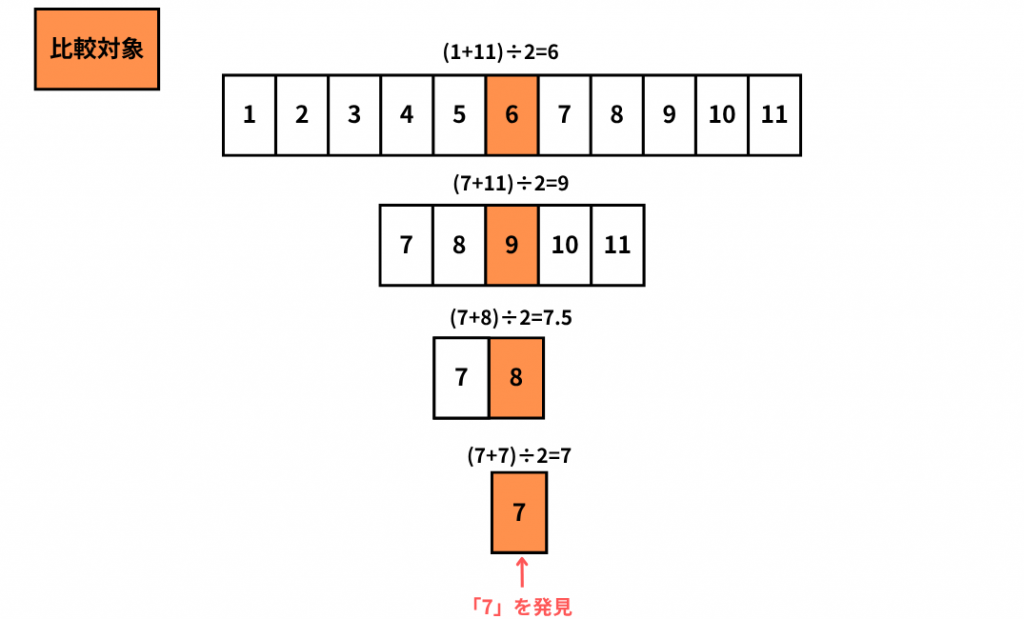
まず、「1~11」の範囲の中の、真ん中は「6」となります。この「6」と「7」を比較します。
この場合「7」の方が大きいので、「7」が含まれるのは「6」より右の範囲に存在するということになります。なぜ右にあるということがわかるかというと前提条件としてこの配列はデータを昇順で整列させているというものがあるためです。
次に「7~9」の範囲の真ん中は「9」です。「7」と「9」を比較すると「9」より小さいので「7」は左のグループに入っていることがわかります、「7~8」の範囲の真ん中は「8」です。(今回は小数現部分を繰り上げましたが、切り捨てでも問題ありません!)「7」と「8」を比較すると「8」の方が大きいので「7」は「8」より左のグループに入っていることがわかります。
最後に「7~7」の範囲の真ん中は「7」です「7」と「7」を比較すると同値なので探索完了となります。
再帰的アルゴリズム
再帰的アルゴリズムというのは、処理の中で自分自身を呼び出すアルゴリズムのことです。
…どういう意味だってばよ(-_-;)
「再帰」というのは「繰り返し」を意味です。また、処理の途中で自分自身を呼び出す関数を再帰呼び出しと言い、再帰呼び出しがある関数のことを再帰関数といいます。
基本情報技術者試験においては再帰的アルゴリズムは主に「余剰」「総和」「階乗」のいずれかを求める際に出題されています。
| 用途 | 詳細 |
|---|---|
| 余剰 | 数式で「」演算子で計算される、割り算のあまりのこと。 例: |
| 総和 | 数式で「」演算子で計算される、与えられた数の合計のこと。 例: |
| 階上 | 数式で「!」演算子で計算される、1~nまですべての整数を掛け算した数のこと。 例: |
では例として「総和」を求めるための再帰的アルゴリズムをご紹介いたします。
今回紹介するアルゴリズムの表現方法の4つは基本情報技術者試験においても頻出のものとなりますのでしっかり理解しておきましょう!
例題:1~10までの整数の「総和」を求めよ。
文章で表現
では例題を文章で表現してみましょう!ここでは計算結果を「sum」としたし算を試行する回数を「n」とします。
①sum←0
n←10
②n>1ならば③へ、n≦1なら⑤へ
③sum←sum+n
④n←n-1
②に戻る
⑤sum=sum+1
⑥sumを返す
上記の文章で表したアルゴリズムでは1~10までの総数の総和(sum)を逆順(0+10+9+・・・+2+1の順)で求めており、②~④を繰り返していることがわかるので再帰的アルゴリズムといえます。
流れ図で表現
例題を「流れ図」で表現するとどうなるでしょうか。実際に見ていきましょう!
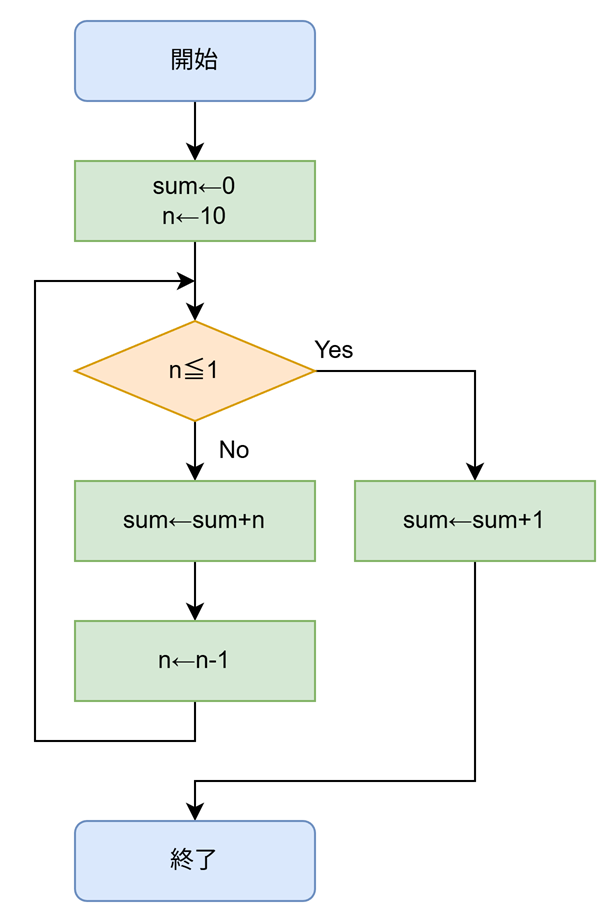
ひし形の部分は条件分岐になっています「n≦1」が成り立つならYesの矢印、成り立たたいならNoの矢印に進みます。
数式で表現
では例題を「数式」で表現するとどうなるでしょうか。
上の数式で「」の箇所がありますが、これはの場合に「自分自身の呼び出し」を行っています。ただ、引数は最初の引数と異なる値を渡しています。処理の中で自分自身を呼び出している箇所が再帰的アルゴリズムとなります。
プログラム言語で表現
では最後に例題を「プログラム言語」で表現してみましょう!
f(x){
if(x < = 1){
return 0;
}else{
return x + (x - 1);
}
}まとめ
いかがだったでしょうか。今回はアルゴリズムについて学びました!
基本情報技術者試験において問われるアルゴリズムには以下のようなものがありました。
■整列アルゴリズム
・バブルソート
・選択ソート
・挿入ソート
・クイックソート
■探索アルゴリズム
・線形探索法
・ハッシュ法
・2分探索法
■再帰的アルゴリズム
・総和
・余剰
・階上
また、アルゴリズムを表現する方法についても学びました。アルゴリズムの表現方法には以下のようなものがあります。
■文章
■流れ図
■数式
■プログラム言語
次回はアルゴリズムのオーダー(計算量)についてご紹介いたします!

コメント