
今回は、データ構造についてご紹介します!
普段みなさんは暗記しないといけないときどのように暗記していますか?
おそらくほとんどの人が繰り返し繰り返し学習しないと覚えられませんよね。
コンピュータの場合はどうでしょうか?
もしあなたがテキストファイルを作ったとして次開いたらあなたが入力したものが全部正確に出てきますね!コンピュータはテキスト、画像、音声、動画など複雑な情報でも迷わず処理できてしまいます。(羨ましい限りです…)
ではコンピュータはどのように情報を取り扱っているのか見ていきましょう。
コンピュータが扱う情報
コンピュータが取り扱う情報のことは「データ」と呼ばれています。データはコンピュータ内部にある「主記憶装置」「補助記憶装置」などに保存されています。(主記憶装置、補助記憶装置などについては別記事にいたします!)
コンピュータの処理能力というのは基本的にデータの並べ方によりかなり変わってしまいます。
したがって記憶装置(主記憶装置、補助記憶装置などのこと)に保存されるデータは状況によって色々な方式で並べられています。この記憶装置上のデータの並べ方のことを「データ構造」と呼びます。
データ構造の特徴
データ構造には以下の5種類があります。
①スタック
②キュー
③配列
④連結リスト
⑤木構造
これまでの基本情報技術者しけんにおいても①~⑤の種類と特徴が問われています。
それではこれらのデータ構造の特徴を一つ一つ見ていきましょう!
スタック
スタックというのはデータを一列に並べ、最後に格納したデータを最初に取り出すデータ構造です。イメージは「チェストに入れられたタオル」です。
ここでは1枚のタオルをデータとします。洗濯が終わって畳んでチェストに収めていきます。
そうすると、タオルは積み上げられ上へ上へ重ねられます。では使うときはどうでしょうか?
そう、上から使いますよね。(私はお気に入りのタオルを使おうとしてチェストの中ぐちゃぐちゃにしてよく怒られていました笑)ということで、ここで言いたいのは「真ん中にあるタオルは使えない」ということです。つまりスタック構造では行った処理の過程を保存しているのでコンピュータはどのタイミングでも元の処理まで戻ることができます。これがスタックの最大の特徴となっています。
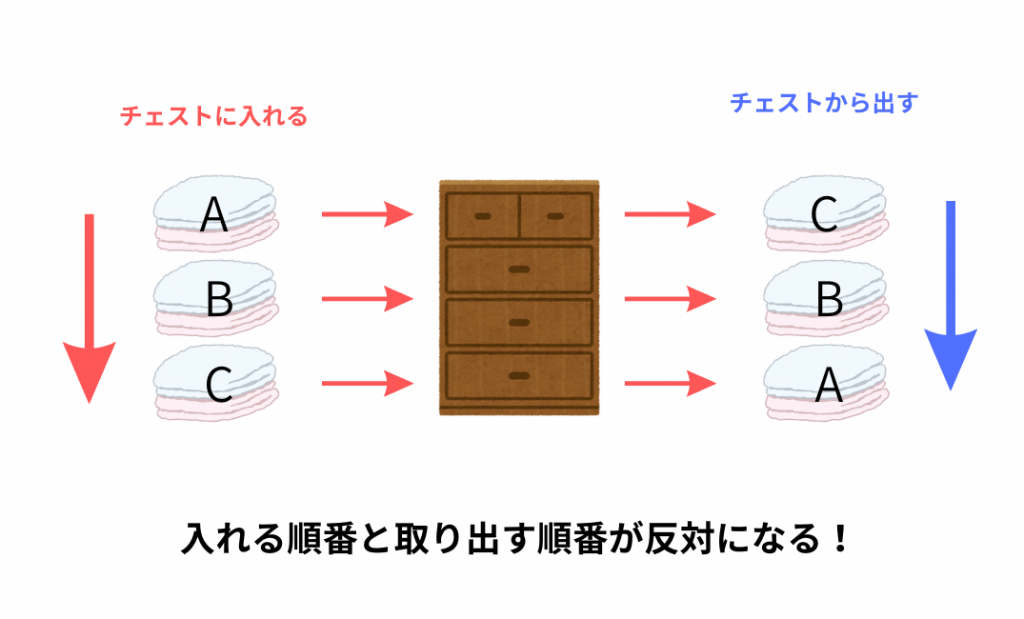
では、このタオルの例を正確な言葉に置き換えていきましょう!
スタック(チェスト)にデータを格納(タオルを入れる)ことを「push」といいます。
「A」とうデータをスタックに格納する場合は「push A」となります。
ではスタック(チェスト)からデータを取り出す(タオルを出す)ことを「pop」といいます。
ここで気を付けてほしいのは「push」の時のように「pop A」みたいにはならない点です。
なぜかって…。タオルを真ん中から使うとお母さんに怒られるからです笑
つまり、スタックの場合は取り出すときは必ず最上部からとなるので「pop」だけでデータが取り出せるんですね!
このような、後に入れたデータを先に出すアルゴリズムのことを後入れ先出し(LIFO:Last In First Out)といいます。
キュー
キューというのは、データを1列に並べ、最初に格納したデータを最初に取り出すデータ構造のことをいいます。キューは「待ち行列」ともいいます。イメージは「ラーメン屋さんの行列」です。
ここでは一人のお客さんがデータです。割り込みをする非常識な人がいないとして、お客さんは列の最後尾に並びます。そして最初に並んだ人から順番にラーメンにありつけます。
ということでここで言いたいのは「並んだ順番通りにラーメンを食べられる」ということです。
つまりキューではデータを入力した順番通りに処理できるということです。
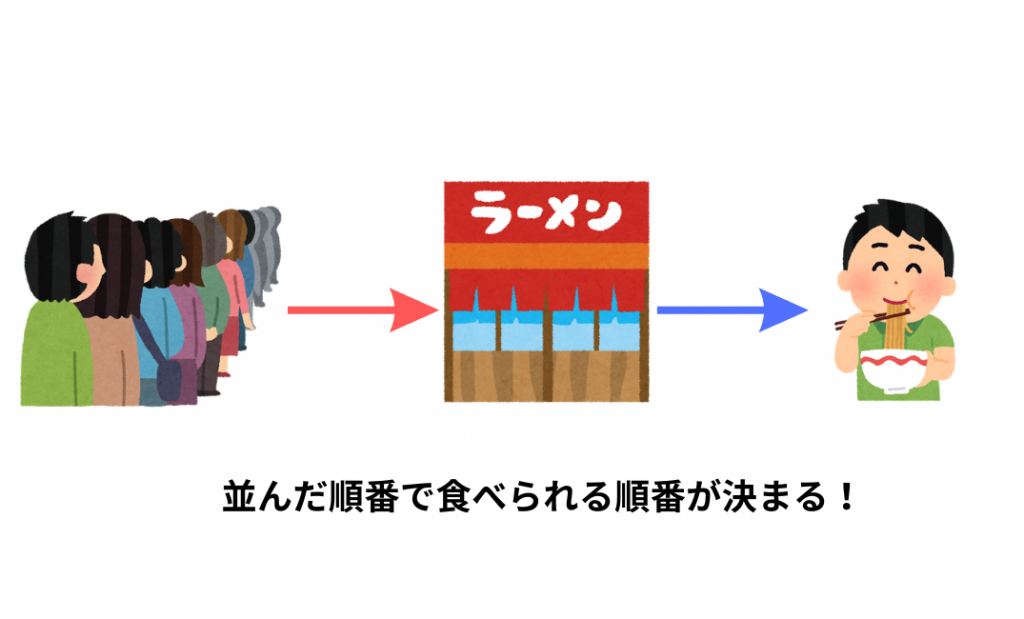
では、このラーメン屋の例を正確な言葉に置き換えていきましょう!
ラーメン屋(キュー)に、お客さん(データ)が並ぶことを「enqueue」といいます。
Aというデータをキューに入れる場合は「enqueue A」となります。
反対にお客さん(データ)が、食べ終わってラーメン屋(キュー)から出ることを「dequeue」といいます。スタックのときと同様、取り出すときは最初に並んだ人からとなるので「dequeue A」といったようにデータを指定する必要はありません。
このような、先に入れたデータを先に出すアルゴリズムのことを先入れ先出し(FIFO:First In First Out)といいます。
配列
配列というのは、データを表形式に並べたデータ構造のことをいいます。
配列では一つ一つのデータのことを「要素」といい、要素の位置を表す数を「要素番号」といいます。
1次元配列
配列の中でも要素が一列に並んでいる配列を1次元配列といいます。
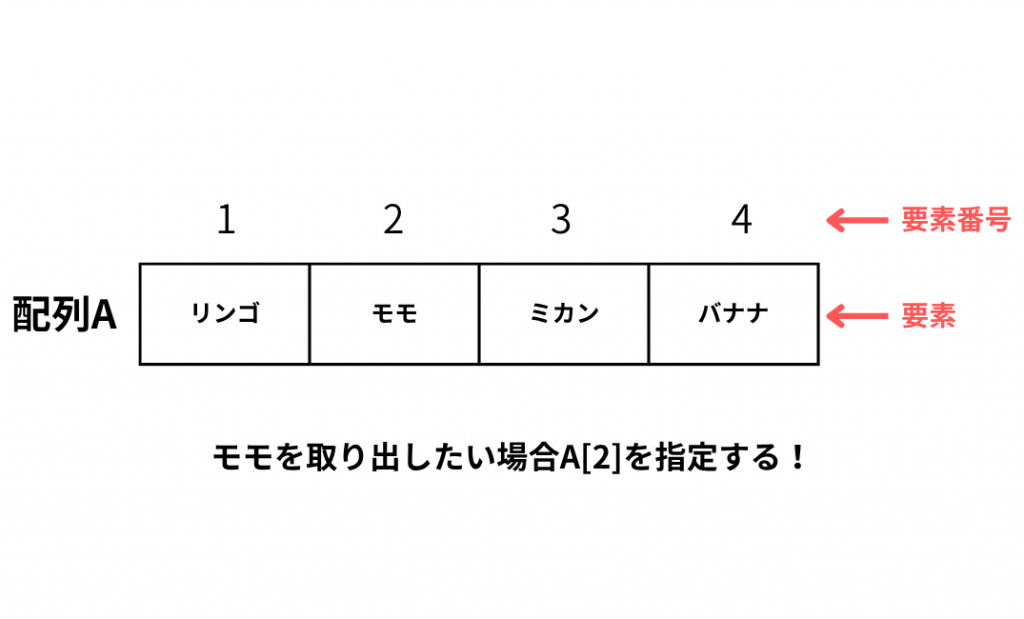
配列から1つの要素を取り出したい場合は、配列名(今回の場合だとA)のあとに「 [ ] 」をつけ、そのなかに取り出したい要素番号を書きます。上の図の例だと、配列Aの先頭から2番目の要素の「モモ」を取り出しておりその際は「A[2]」と書く。
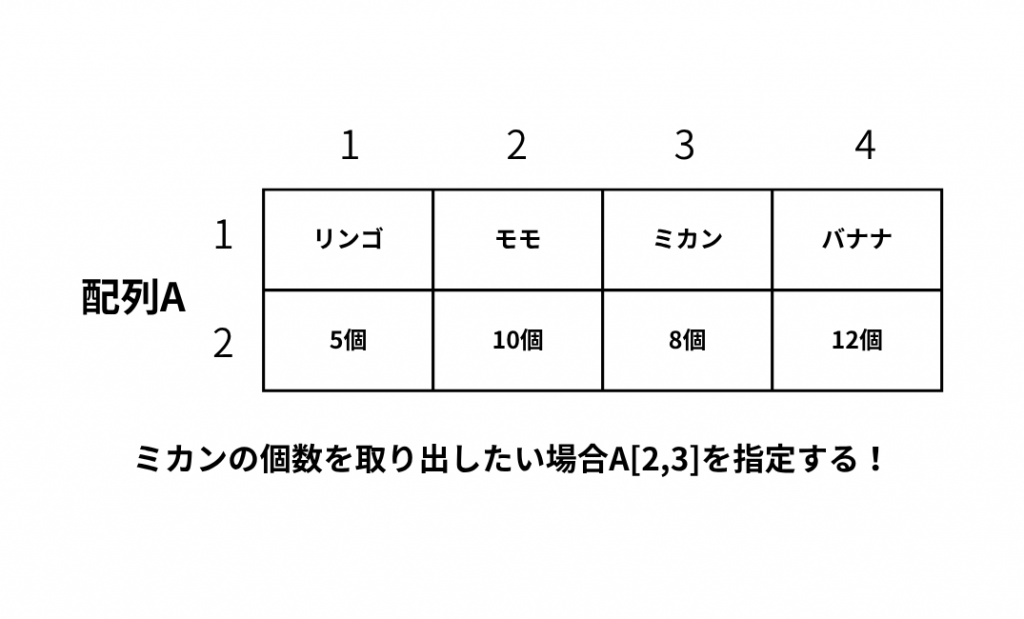
2次元配列
配列の中でも要素が縦横に並ぶ配列のことを2次元配列といいます。
2次元配列において、要素の横の並びを「行」、縦の並びのことを「列」といいます。
2次元配列から1つの要素を取り出す場合は要素番号を「行番号、列番号」の順に指定します。
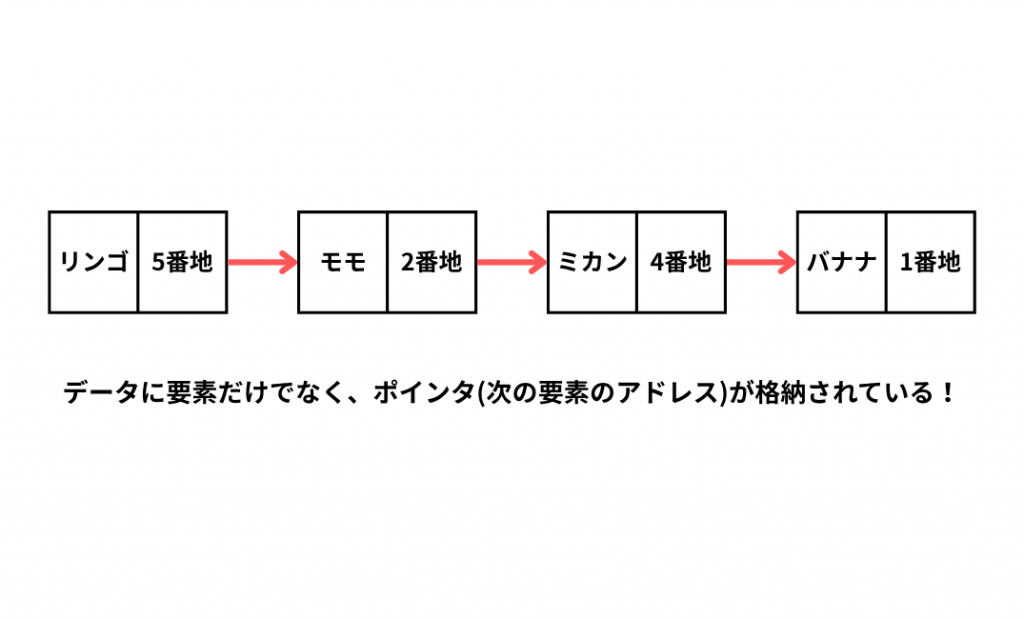
連結リスト
連結リストというのはデータを数珠繋ぎに並べたデータ構造のことをいいます。
連結リストにおいても配列と同じように一つ一つのデータを「要素」と呼びます。
ただし、連結リストの要素は配列の要素と異なりデータに「ポインタ」が付きます。
ポインタというのは次の要素のアドレス(主記憶装置上のデータの場所)を示すものです。
連結リストではこのポインタを用いることによって要素を数珠繋ぎにします。
コンピュータはポインタに格納されているアドレスをたどることにより、目的のデータにたどり着くことができます。
記憶装置との関係は以下の図のようになっています。
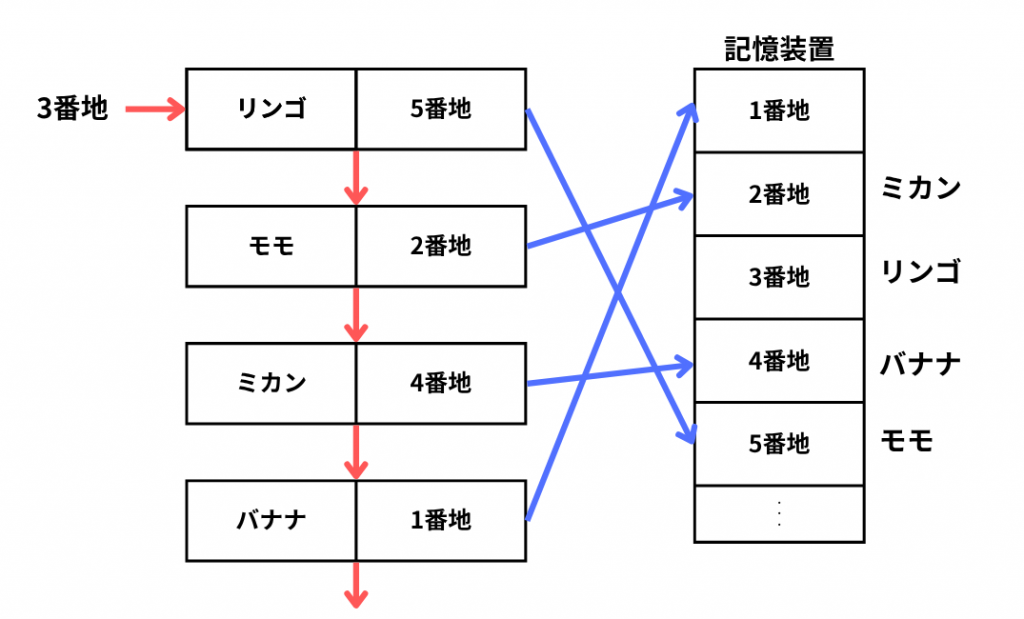
ここで鋭い人は気づいたかもしれませんが、配列と連結リストではデータへのアクセス方法が違います。といのもデータが順番に並んでいることに関しては同じですが、配列では要素番号を使用することでデータに直接アクセスできましたが、連結リストでは先頭から順番に要素をたどることによって目的のデータにアクセスする必要があります。つまり、連結リストは要素数が多ければ多いほどデータへのアクセスには時間がかかってしまうのです。
「え、じゃあ配列を使って連結リストなんて使う意味ないじゃん」と思ったそこのあなた!
はいその通りです。単純に読み取るだけであればそちらのほうが効率が良いです。
しかしデータを挿入するとき、または削除するときに関しては連結リストのほうが有利となります。
配列の要素を挿入、削除しようとした場合、後ろの要素をすべて一つづつずらす必要があります。そのため要素数が多ければ多いほど、ずらすための処理時間が長くなります。
一方で連結リストは、ポインタを変更するだけでデータを挿入、削除することができるので配列より早く処理できます。
ここは試験においてもプログラミングにおいても非常に重要となりますので必ず覚えておきましょう!(C言語とかぜひ触ってもらってポインタで苦しんでください笑。苦しいですが糧になります。)
連結リストの種類
実は連結リストにはいくつか種類があります。基本情報技術者試験では「連結リスト」とは違った表現で記載されている可能性もあるので以下のような連結リストの名前は覚えておいてください。
■方向性の分類
| 種類 | 詳細 |
|---|---|
| 単方向リスト | リストの先頭から末尾まで一方通行の連結リスト。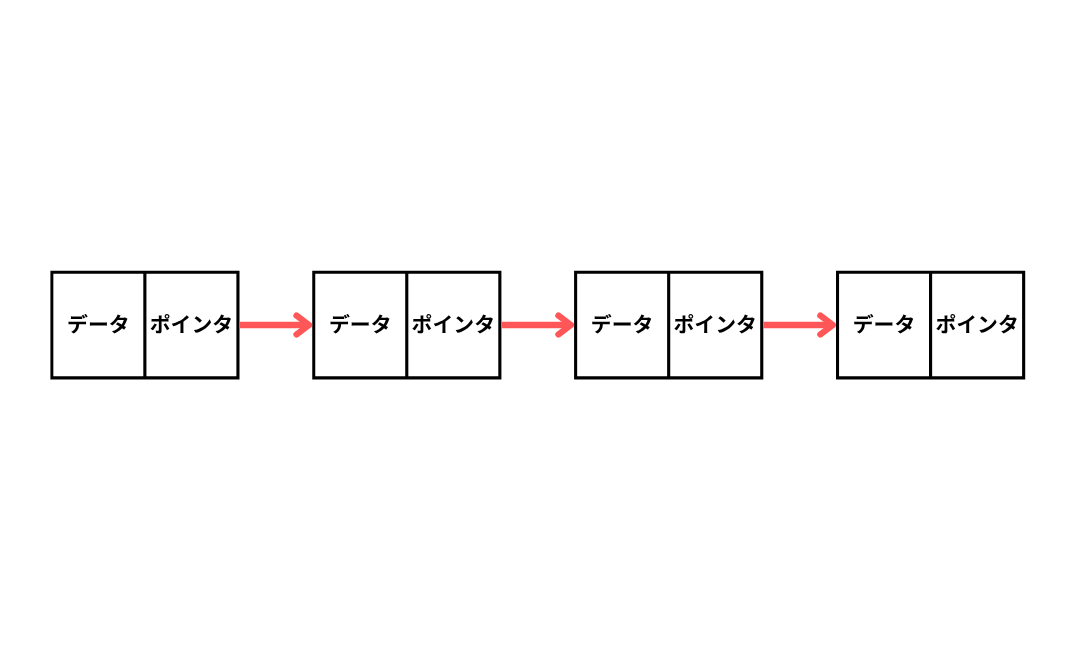 |
| 双方向リスト | データを双方向につなげた連結リスト。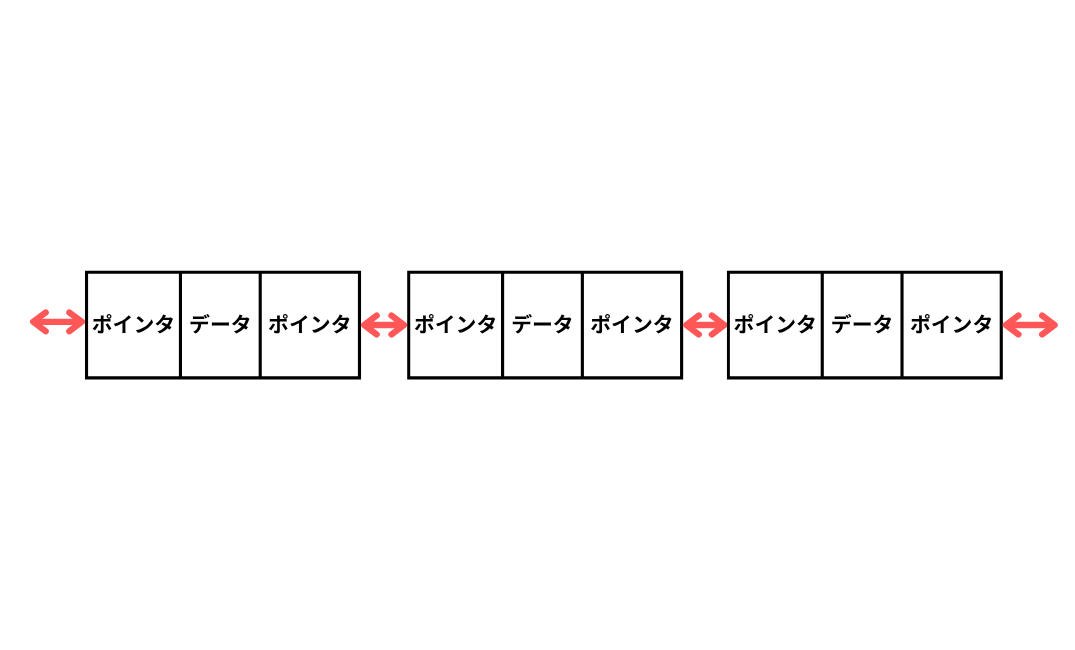 |
■形の分類
| 種類 | 詳細 |
|---|---|
| 線形リスト | リストの先頭から末尾にかけて直線状に要素が繋がっている連結リスト。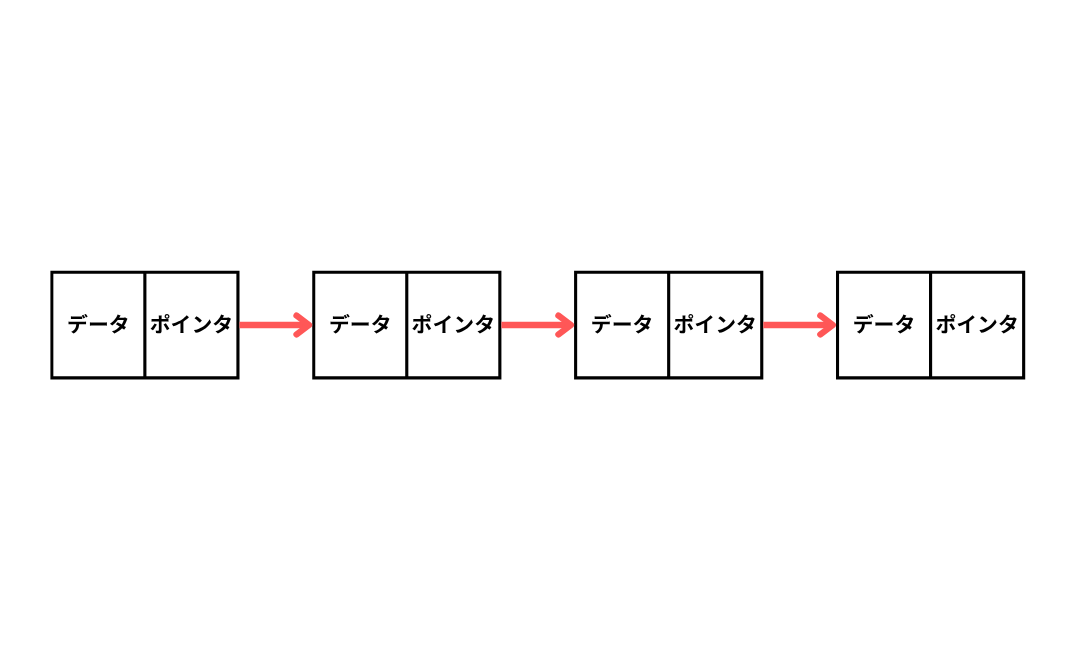 |
| 環状リスト | リストの先頭と末尾が繋がって環状になっている連結リスト。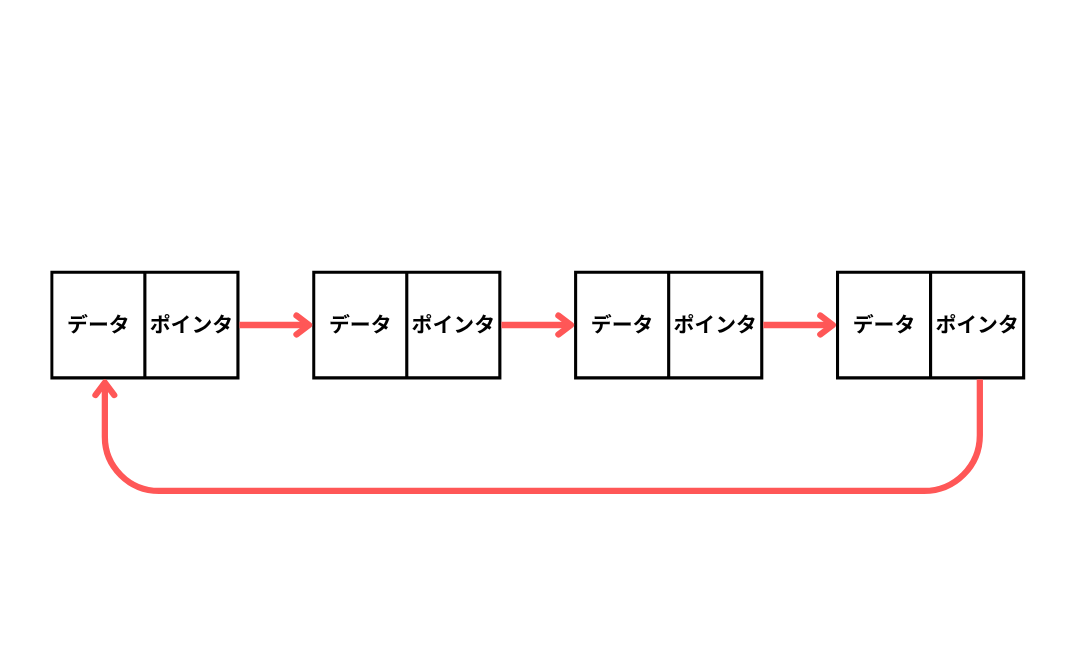 |
木構造
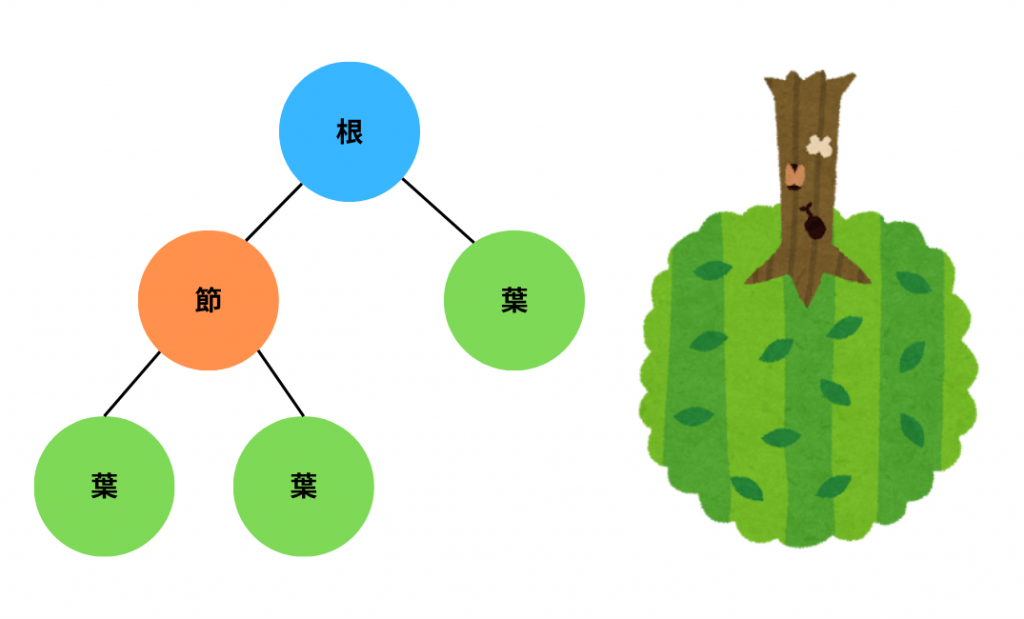
木構造というのは階層構造をもつデータ構造のことをいいます。
その名の通り木を逆さまにしたような形をしていることからこの名がついています。
木構造の「〇」で表現された箇所を「節」といいます。木構造においてはこの節にデータが格納されています。節の中でも一番上の節を「根」といい、反対に一番下の節を「葉」といいます。
(わかりやすくていいですね笑)
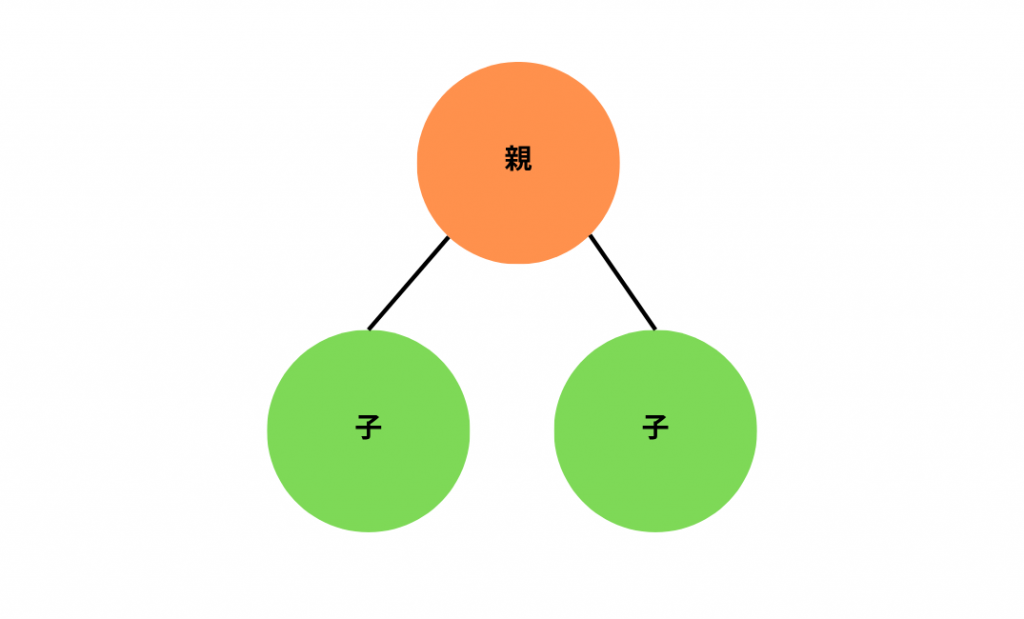
木構造において節どうしには親子関係があります。
分岐元のことを「親」、分岐先のことを「子」といいます。
親はいくつでも子を持つことができ、木構造の中でも親が0-2個の子を持つ木構造を2分木といい、親が0-3個の子を持つ木構造を3分木といいます。
この法則性を一般化して、親が0-n個の子を持つ木構造のことをn分木といいます。
つまり分木というのは、節が最大で何個の子に分かれるのかを表現しているんですね。
2分探索木
2分木の中でも、親子の値が以下のような関係性になっているものを「2分探索木」といいます。
左の子<親<右の子
ここでいう「子」というのは「親よりも下にあるデータ」という意味です。
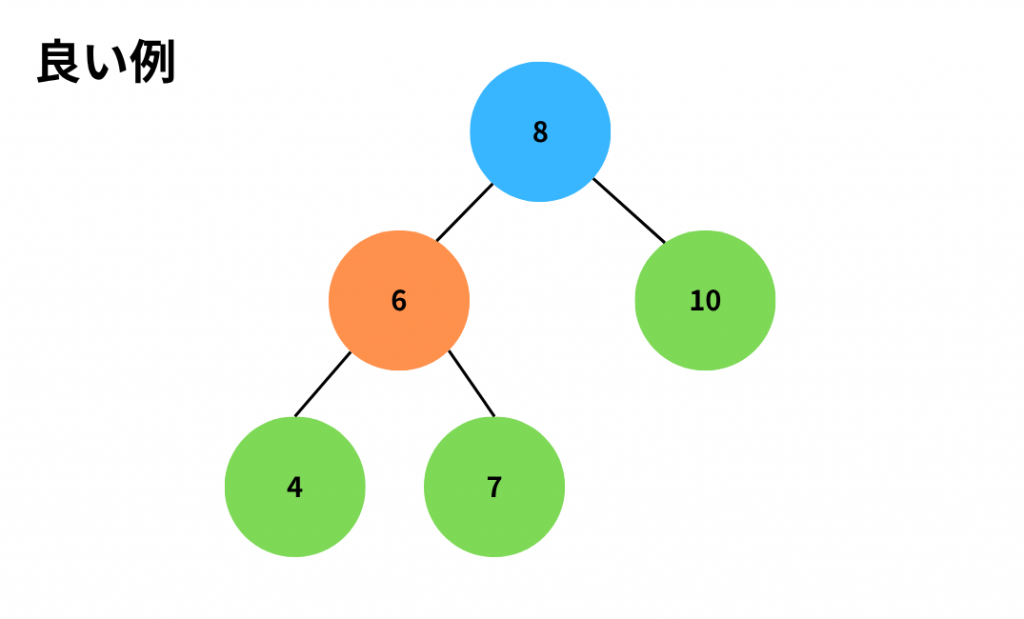
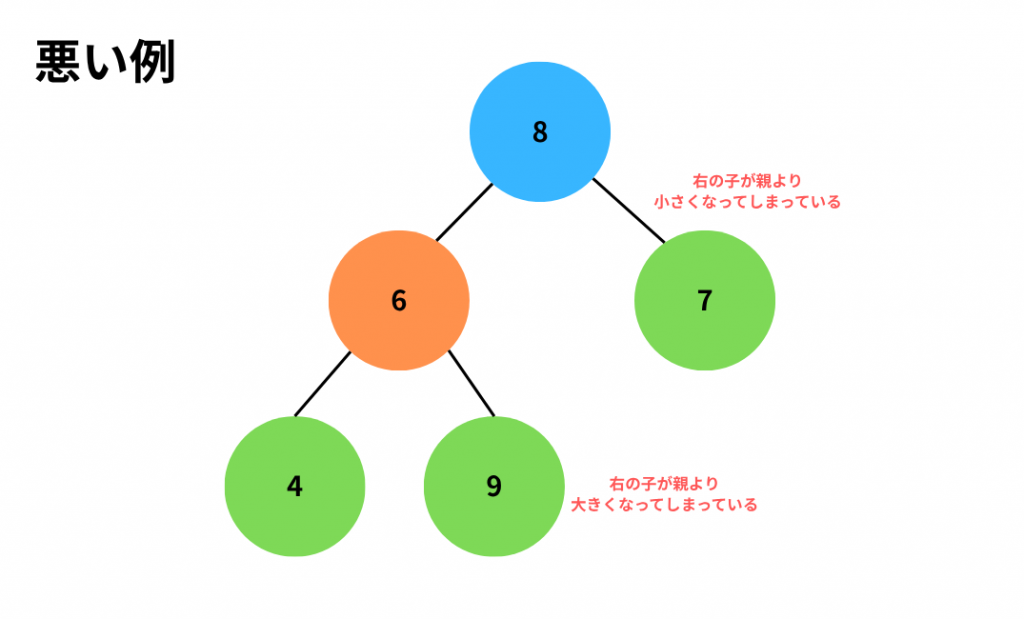
悪い例では2か所が2分探索木の条件に当てはまっていません。
一つ目は7が8の子なのに8より小さいというところ、二つ目は9が8より大きいというところです。
したがって悪い例の2分木は2分探索木とは言えません。
なぜ、2分木を2分探索木のように並べるのかというとデータをの探索速度が上がるからです。
2分探索木では根から葉までの階層の数だけ値を調べてあげることによって目的のデータを見つけ出すことが可能です。
一方、親子関係が無関係に繋がれた木構造では節を一つ一つみないとデータを見つけることはできません。
2分探索木において、大事なのは親とその子、その子孫のそのすべてが条件に当てはまっていないといけないということです。
まとめ
いかがだったでしょうか!今回は基本情報技術者試験で問われるデータ構造についてご紹介いたしました。データ構造は一長一短があるため都度都度適したデータ構造を選択することが必要です。
①コンピュータで扱う情報のことを「データ」という
②記憶装置上のデータの並べ方を「データ構造」という
③データ構造には以下の種類がある
・スタック
・キュー
・配列
・連結リスト
・木構造
④スタックは後入れ先出し(LIFO)のデータ構造
⑤キューは先入れ先出し(FIFO)のデータ構造
⑥配列はデータを表形式に並べたデータ構造
⑦連結リストはデータをポインタを使うことで数珠繋ぎに並べたデータ構造
連結リストには以下のような種類がある
・単方向リスト
・双方向リスト
・線形リスト
・環状リスト
⑧配列と連結リストでは、参照は配列のほうが得意だが、データの挿入・削除においては連結リストのほうが得意
⑨木構造は階層構造を持つデータ構造
⑩親が0-n個の子を持つ分木をn分木という
⑪二分木のうち「左の子<親<右の子」の上限がすべての親子関係で成り立つ場合2分探索木という


コメント